如何在Ubuntu 20.04上安装和配置Apache Hadoop
如何在Ubuntu 20.04上安装和配置Apache Hadoop
Apache Hadoop是一个开放源代码框架,用于管理,存储和处理在集群系统下运行的各种大数据应用程序的数据。 它用Java编写,并带有一些C和Shell脚本中的本地代码。 它使用分布式文件系统(HDFS),并从单个服务器扩展到数千台计算机。
Apache Hadoop基于四个主要组件:
- Hadoop Common:这是其他Hadoop模块所需的实用程序和库的集合。
- HDFS:也称为Hadoop分布式文件系统,分布在多个节点上。
- MapReduce:这是一个用于编写应用程序以处理大量数据的框架。
- Hadoop YARN:Hadoop的资源管理层也称为“另一个资源协商者”。
在本教程中,我们将说明如何在Ubuntu 20.04上设置单节点Hadoop集群。
先决条件
- 运行带有4 GB RAM的Ubuntu 20.04的服务器。
- 在您的服务器上配置了root密码。
更新系统软件包
开始之前,建议将系统软件包更新为最新版本。 您可以使用以下命令进行操作:
apt-get update -y
apt-get upgrade -y系统更新后,请重新启动以实施更改。
安装Java
Apache Hadoop是基于Java的应用程序。 因此,您将需要在系统中安装Java。 您可以使用以下命令进行安装:
apt-get install default-jdk default-jre -y安装后,您可以使用以下命令来验证Java的安装版本:
java -version您应该获得以下输出:
openjdk version "11.0.7" 2020-04-14 OpenJDK Runtime Environment (build 11.0.7+10-post-Ubuntu-3ubuntu1) OpenJDK 64-Bit Server VM (build 11.0.7+10-post-Ubuntu-3ubuntu1, mixed mode, sharing)
创建Hadoop用户并设置无密码SSH
首先,使用以下命令创建一个名为hadoop的新用户:
adduser hadoop接下来,将hadoop用户添加到sudo组
usermod -aG sudo hadoop
接下来,使用hadoop用户登录并使用以下命令生成SSH密钥对:
su - hadoop
ssh-keygen -t rsa您应该获得以下输出:
Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Created directory '/home/hadoop/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub The key fingerprint is: SHA256:HG2K6x1aCGuJMqRKJb+GKIDRdKCd8LXnGsB7WSxApno [email protected] The key's randomart image is: +---[RSA 3072]----+ |..=.. | | O.+.o . | |oo*.o + . o | |o .o * o + | |o+E.= o S | |=.+o * o | |*.o.= o o | |=+ o.. + . | |o .. o . | +----[SHA256]-----+
接下来,将此密钥添加到Authorized ssh密钥并给予适当的许可:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys接下来,使用以下命令验证无密码的SSH:
ssh localhost登录后无需密码即可继续下一步。
安装Hadoop
首先,使用hadoop用户登录并使用以下命令下载最新版本的Hadoop:
su - hadoop
wget https://downloads.apache.org/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz下载完成后,使用以下命令解压缩下载的文件:
tar -xvzf hadoop-3.2.1.tar.gz接下来,将提取的目录移动到/ usr / local /:
sudo mv hadoop-3.2.1 /usr/local/hadoop接下来,使用以下命令创建一个目录来存储日志:
sudo mkdir /usr/local/hadoop/logs接下来,将hadoop目录的所有权更改为hadoop:Advertisement.banner-1 {text-align:center; padding-top:10pximportant; padding-bottom:10pximportant; padding-left:0pximportant; padding-right:0pximportant; width:100%important; box-sizing:border-boximportant; background -color:#eeeeeeimportant; border:1px实心#dfdfdf}
sudo chown -R hadoop:hadoop /usr/local/hadoop接下来,您将需要配置Hadoop环境变量。 您可以通过编辑〜/ .bashrc文件来实现:
nano ~/.bashrc添加以下行:
export HADOOP_HOME=/usr/local/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export P新高=$P新高:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
完成后保存并关闭文件。 然后,使用以下命令激活环境变量:
source ~/.bashrc配置Hadoop
在本节中,我们将学习如何在单个节点上设置Hadoop。
配置Java环境变量
接下来,您将需要在hadoop-env.sh中定义Java环境变量,以配置YARN,HDFS,MapReduce和Hadoop相关的项目设置。
首先,使用以下命令找到正确的Java路径:
which javac您应该看到以下输出:
/usr/bin/javac
接下来,使用以下命令找到OpenJDK目录:
readlink -f /usr/bin/javac您应该看到以下输出:
/usr/lib/jvm/java-11-openjdk-amd64/bin/javac
接下来,编辑hadoop-env.sh文件并定义Java路径:
sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh添加以下行:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_CLASSP新高+=" $HADOOP_HOME/lib/*.jar"
接下来,您还需要下载Javax激活文件。 您可以使用以下命令下载它:
cd /usr/local/hadoop/lib
sudo wget https://jcenter.bintray.com/javax/activation/javax.activation-api/1.2.0/javax.activation-api-1.2.0.jar现在,您可以使用以下命令来验证Hadoop版本:
hadoop version您应该获得以下输出:
Hadoop 3.2.1 Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r b3cbbb467e22ea829b3808f4b7b01d07e0bf3842 Compiled by rohithsharmaks on 2019-09-10T15:56Z Compiled with protoc 2.5.0 From source with checksum 776eaf9eee9c0ffc370bcbc1888737 This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.2.1.jar
配置core-site.xml文件
接下来,您将需要为NameNode指定URL。 您可以通过编辑core-site.xml文件来实现:
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xml添加以下行:
fs.default.name hdfs://0.0.0.0:9000 The default file system URI
完成后保存并关闭文件:
配置hdfs-site.xml文件
接下来,您将需要定义用于存储节点元数据,fsimage文件和编辑日志文件的位置。 您可以通过编辑hdfs-site.xml文件来实现。 首先,创建用于存储节点元数据的目录:
sudo mkdir -p /home/hadoop/hdfs/{namenode,datanode}
sudo chown -R hadoop:hadoop /home/hadoop/hdfs接下来,编辑hdfs-site.xml文件并定义目录的位置:
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml添加以下行:
dfs.replication 1 dfs.name.dir file:///home/hadoop/hdfs/namenode dfs.data.dir file:///home/hadoop/hdfs/datanode
保存并关闭文件。
配置mapred-site.xml文件
接下来,您将需要定义MapReduce值。 您可以通过编辑mapred-site.xml文件来定义它:
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xml添加以下行:
mapreduce.framework.name yarn
保存并关闭文件。
配置yarn-site.xml文件
接下来,您将需要编辑yarn-site.xml文件并定义与YARN相关的设置:
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xml添加以下行:
yarn.nodemanager.aux-services mapreduce_shuffle
完成后保存并关闭文件。
格式化HDFS NameNode
接下来,您将需要验证Hadoop配置并格式化HDFS NameNode。
首先,以Hadoop用户身份登录并使用以下命令格式化HDFS NameNode:
su - hadoop
hdfs namenode -format您应该获得以下输出:
2020-06-07 11:35:57,691 INFO util.GSet: VM type = 64-bit 2020-06-07 11:35:57,692 INFO util.GSet: 0.25% max memory 1.9 GB = 5.0 MB 2020-06-07 11:35:57,692 INFO util.GSet: capacity = 2^19 = 524288 entries 2020-06-07 11:35:57,706 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10 2020-06-07 11:35:57,706 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10 2020-06-07 11:35:57,706 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25 2020-06-07 11:35:57,710 INFO namenode.FSNamesystem: Retry cache on namenode is enabled 2020-06-07 11:35:57,710 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis 2020-06-07 11:35:57,712 INFO util.GSet: Computing capacity for map NameNodeRetryCache 2020-06-07 11:35:57,712 INFO util.GSet: VM type = 64-bit 2020-06-07 11:35:57,712 INFO util.GSet: 0.029999999329447746% max memory 1.9 GB = 611.9 KB 2020-06-07 11:35:57,712 INFO util.GSet: capacity = 2^16 = 65536 entries 2020-06-07 11:35:57,743 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1242120599-69.87.216.36-1591529757733 2020-06-07 11:35:57,763 INFO common.Storage: Storage directory /home/hadoop/hdfs/namenode has been successfully formatted. 2020-06-07 11:35:57,817 INFO namenode.FSImageFormatProtobuf: Saving image file /home/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 using no compression 2020-06-07 11:35:57,972 INFO namenode.FSImageFormatProtobuf: Image file /home/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 of size 398 bytes saved in 0 seconds . 2020-06-07 11:35:57,987 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 2020-06-07 11:35:58,000 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown. 2020-06-07 11:35:58,003 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at ubuntu2004/69.87.216.36 ************************************************************/
启动Hadoop集群
首先,使用以下命令启动NameNode和DataNode:
start-dfs.sh您应该获得以下输出:
Starting namenodes on [0.0.0.0] Starting datanodes Starting secondary namenodes [ubuntu2004]
接下来,通过运行以下命令来启动YARN资源和节点管理器:
start-yarn.sh您应该获得以下输出:
Starting resourcemanager Starting nodemanagers
您现在可以使用以下命令验证它们:
jps您应该获得以下输出:
5047 NameNode 5850 Jps 5326 SecondaryNameNode 5151 DataNode
访问Hadoop Web界面
现在,您可以使用URL http:// your-server-ip:9870访问Hadoop NameNode。 您应该看到以下屏幕:
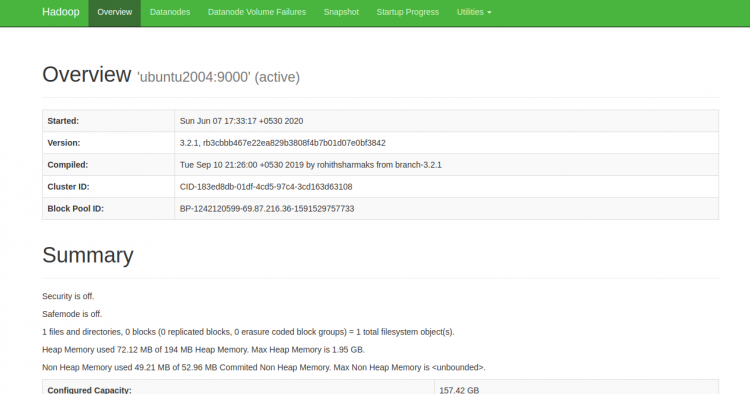
您也可以使用URL http:// your-server-ip:9864访问单个DataNode。 您应该看到以下屏幕:
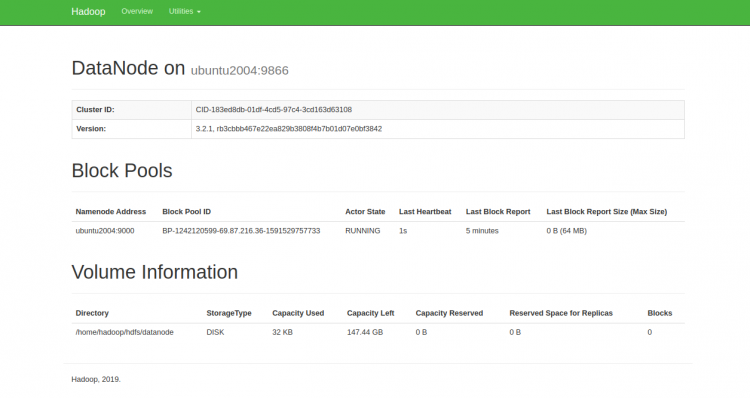
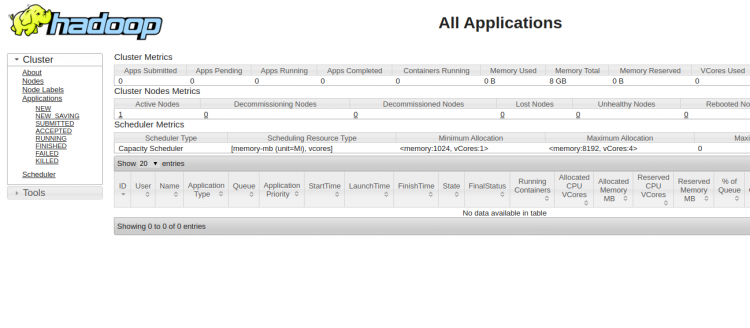
要访问YARN浏览器,请使用URL http:// your-server-ip:8088。 您应该看到以下屏幕:
结论
恭喜你 您已在单个节点上成功安装了Hadoop。 现在,您可以开始探索基本的HDFS命令并设计一个完全分布式的Hadoop集群。 如有任何问题,随时问我。