使用Docker Swarm部署跨機器的基於Kafka的多伺服器Hyperledger Fabric網路
使用Docker Swarm(多個主機)部署跨機器的基於Kafka的多訂購者Hyperledger Fabric網路
關於在多個主機或伺服器上創建Hyperledger Fabric網路的結構化教程非常少。您只能在官方的Hyperledger Fabric文檔中找到構建單機網路的指南,該文檔根本不是分散式和去中心化的。今天,讓我們一起做吧
什麼是Docker Swarm?
Docker Swarm是一種集群管理工具,可以在不同的計算機上實現不同容器的通信。我們還將使用覆蓋網路,它是Docker Swarm頂部的連接層。有關詳細信息,請訪問https://docs.docker.com/engine/swarm/和https://docs.docker.com/network/overlay/
在我們開始之前……必須做
最好
備註
它基於Hyperledger Fabric版本1.1,儘管最新版本也可以使用
網路架構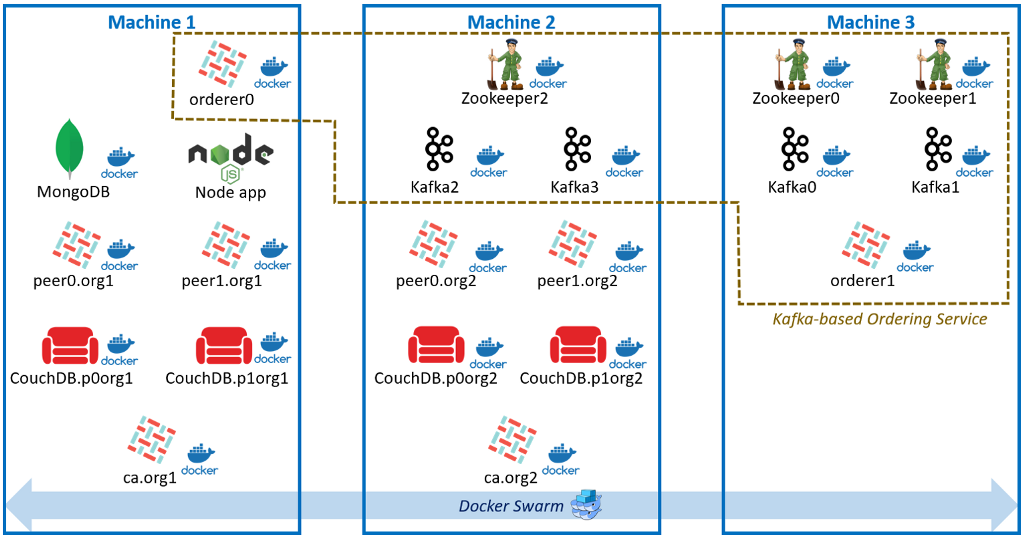 網路架構
網路架構
上圖顯示了整個網路架構。組織1和組織2組件分別位於機器1和機器2中。基於Kafka的訂購服務包括部署在三台機器中的組件。除節點應用程序之外的所有組件都使用Docker進行容器化。除MongoDB之外的所有容器都通過Docker Swarm覆蓋網路相互通信。
每個組件的功能:
- 同行:區塊鏈分類帳和鏈代碼引擎(智能合約)
- CouchDB:具有豐富查詢功能的狀態資料庫
- CA:註冊並註冊新用戶
- MongoDB:存儲用戶憑據
- Orderer:訂購交易並將它們打包成一個塊
- 卡夫卡:共識協議
- Zookeeper:Kafka的註冊和配置服務
- 節點應用程序:用於與區塊鏈交互的API伺服器
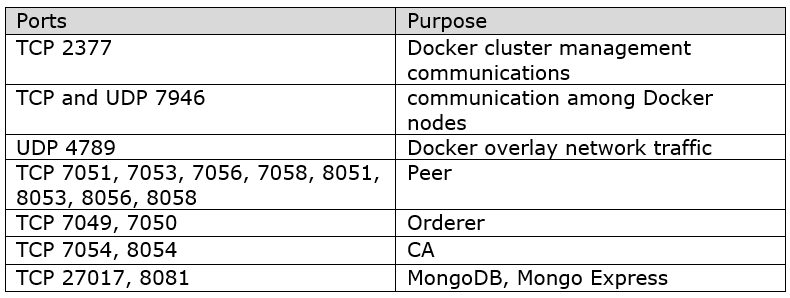 防火牆設置
防火牆設置
需要公開上面列出的埠以促進跨機器網路。
警告:MongoDB和Mongo Express應該暴露在生產環境中的所有外部IP中。
編輯網路配置文件
在hyperledger-fabric-technical-tutorial / balance-transfer / artifacts / network-config.yaml中,將orderer1和所有Org 2組件的默認IP地址更改為Machine 2的實際IP地址。
此文件提供Org 1,Org 2組件和兩個orderers的網路信息,供節點應用程序發送API請求。由於節點應用程序未部署在Docker Swarm網路中,因此必須通過指定IP地址來完成外部通信。
由於節點應用程序不直接與Kafka和Zookeeper群集通信,因此不包括其IP地址。
MongoDB連接配置文件在org1.yaml和org2.yaml中編碼。由於MongoDB和節點應用程序位於同一台計算機上,因此使用localhost足以進行通信。
設置Docker Swarm和覆蓋網路
在機器1中,運行docker swarm init以將Swarm網路初始化為管理器。它返回類似於以下結果的內容。
docker swarm join –token SWMTKN-1-4bg8u1sjnk6sjegcdba5f03ij5yespoqn1g3qhji7hn213qyw0-ee8h9oinejen29d1t9r6pw4pf 172.0.0.71:2377
在機器1終端中複製命令並在機器2和機器3中運行以加入Swarm網路。以下是成功回應。
該節點作為工作者加入了一個群。
在機器1中運行docker node ls以列出Swarm網路節點。你應該看到三個節點。
在機器1中,運行docker network create –attachable –driver overlay fabric_net以創建名為fabric_net的覆蓋網路。
在所有三台機器上運行docker network ls。只有機器1顯示fabric_net,因為覆蓋網路只能通過啟動加入該覆蓋網路的docker容器擴展到其他節點。
在機器2和機器3中,運行docker run -itd –name mybusybox –network fabric_net busybox以創建一個加入fabric_net的busybox docker容器。事實上,無論是busybox都沒關係,提出任何容器加入fabric_net都可以產生同樣的效果。
在機器2和機器3中再次運行docker network ls以查看fabric_net是否存在。
如果有任何錯誤,sudo systemctl重新啟動所有三台機器中的docker以重啟Docker引擎或運行docker swarm在所有三台機器中離開–force離開Swarm網路並再次重複上述過程。
網路組件部署
在hyperledger-fabric-technical-tutorial / balance-transfer /目錄中運行以下所有命令。
對於所有機器,
刪除所有現有容器以避免RAM過載。 (確保沒有其他重要的容器在運行)
docker rm -f`docker ps -aq`
清除未使用的Docker成交量
碼頭工人修剪-f
刪除緩存的Docker鏈代碼圖像
docker rmi -f $(docker images | grep「dev | none | test-vp | peer(0-9) – 」| awk'{print $3}')
對於機器3,
docker-compose -f artifacts / docker-compose-kafka.yaml up -d zookeeper0 zookeeper1docker-compose -f artifacts / docker-compose-kafka.yaml up -d kafka0 kafka1docker-compose -f artifacts / docker-compose.yaml up – d orderer1.example.com
對於機器2,
docker-compose -f artifacts / docker-compose-kafka.yaml up -d zookeeper2docker-compose -f artifacts / docker-compose-kafka.yaml up -d kafka2 kafka3docker-compose -f artifacts / docker-compose.yaml up -d peer0.org2.example.com peer1.org2.example.com ca.org2.example.com couchdb0.org2 couchdb1.org2
對於機器1,
docker-compose -f artifacts / docker-compose.yaml up -d orderer0.example.comdocker-compose -f artifacts / docker-compose.yaml up -d peer0.org1.example.com peer1.org1.example.com ca. org1.example.com couchdb0.org1 couchdb1.org1docker-compose -f artifacts / docker-compose-mongo.yaml up -dnpm installnode app
如果您的機器中沒有泊塢窗圖像,泊塢引擎將從互聯網上提取所有圖像。
對於執行順序,應首先部署zookeeper,然後是kafka,其餘部分。
測試
在Machine 1中打開一個新終端並運行./testAPIs.sh -l節點。
如果沒有錯誤,恭喜
您成功部署了跨機器Hyperledger Fabric網路
如果您想了解有關源代碼的更多信息,可以從分支發行版1.1下的github存儲庫下載「Hyperledger Fabric技術指南for Intermediate 開發工程師s.docx」。如果您遇到任何問題,請隨時與我聯繫
最後但並非最不重要的,如果你喜歡,請拍這篇文章吧 🙂
![]()
使用Docker Swarm部署跨機器的基於Kafka的多訂購者Hyperledger Fabric網路最初發布在Coinmonks on Medium上,人們通過突出顯示和回應這個故事來繼續對話。