使用Tensorflow作為二進位分類問題預測加密貨幣價格
介紹
在本教程中,我們將介紹神經網路的原型,該模型將使我們能夠使用Keras和Tensorflow作為我們的主要clarvoyance工具來估計未來的加密貨幣價格(作為二進位分類問題)。
儘管這可能不是解決問題的最佳方法(畢竟,所有投資銀行都在開發這種演算法上投入了數十億美元),但如果我們能夠超過55%的時間解決問題,那麼我們就是有錢了
我們會做什麼
- 使用幣安API下載數據
- 預處理數據
- 訓練我們的模型
- 特徵工程
- 評估性能最佳的模型
使用幣安API下載數據
對於此示例,我們將下載單個調用中可獲取的最大數據量。如果您想訓練更多更好的東西並在現實世界中使用它(不建議這樣做,那麼您可能會浪費真錢),我建議您通過多次通話收集更多數據。
import requests
import json
import pandas as pd
import datetime as dt
START_DATE = '2019-01-01'
END_DATE = '2019-10-01'
INTERVAL = '15m'
def parse_date(x):
return str(int(dt.datetime.fromisoformat(x).timestamp()))
def get_bars(symbol, interval):
root_url = 'https://api.binance.com/api/v1/klines'
url = root_url + '?symbol=' + symbol + '&interval=' + interval + '&startTime=' + parse_date(START_DATE) + '&limit=1000'
data = json.loads(requests.get(url).text)
df = pd.DataFrame(data)
df.columns = ['open_time',
'o', 'h', 'l', 'c', 'v',
'close_time', 'qav', 'num_trades',
'taker_base_vol', 'taker_quote_vol', 'ignore']
df.drop(['ignore', 'close_time'], axis=1, inplace=True)
return df
ethusdt = get_bars('ETHUSDT', INTERVAL)
ethusdt.to_csv('./data.csv', index=False)
在這段簡單的代碼中,我們需要必要的程序包,設置幾個參數(我選擇了15分鐘的時間間隔,但是您可以選擇更精細的時間間隔以進行更高頻率的交易)並設置幾個便利功能,然後將數據保存到csv以供將來重用。這應該是不言自明的,但是如果有什麼讓您感到困惑的話,請隨時發表評論以尋求澄清:)
預處理數據
由於價格加班是順序數據的一種形式,因此我們將使用LSTM層(長期短期記憶)作為我們網路中的第一層。我們希望提供的數據作為事件的序列,這將預測價格在時間t+n,其中t是當前時間和n定義了多遠,我們要預測未來,這樣做我們會養活數據的時間窗口w長度。查看代碼後,一切將變得更加清晰,讓我們開始導入所需的軟體包。
import pandas as pd
import numpy as np
import seaborn as sns
import random
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Dropout
from tensorflow.keras.callbacks import TensorBoard
import time
import matplotlib.pyplot as plt
這將導入Pandas,Numpy,我們訓練模型所需的所有Tensorflow函數以及其他一些有用的軟體包。
接下來,我們要定義一些常量,並從csv載入我們的數據(以防您在其他文件上編寫訓練代碼:
WINDOW = 10 # how many time units we are going to use to evaluate the future value, in our case each time unit is 15 minutes so we are going to look at 15 * 10 = 150 minutes trading data
LOOKAHEAD = 5 # how far ahead we want to estimate if the future prices is going to be higher or lower? In this case is 5 * 15 = 75 minutes in the future
VALIDATION_SAMPLES = 100 # We want to validate our model on data that wasn't used for the training, we are establishing how many data point we are going to use here.
data = pd.read_csv('./data.csv')
data['future_value'] = data['c'].shift(-LOOKAHEAD) # This allows us to define a new column future_value with as the value of c 5 time units in the future
data.drop([
'open_time'
], axis=1, inplace=True) # we don't care about the timestamp for predicting future prices
讓我們定義一個函數,該函數使我們可以定義將來的價格是高於還是低於當前收盤價:
def define_output(last, future):
if future > last:
return 1
else:
return 0
如果價格低於或等於當前收盤價,只需將目標設置為0,如果價格高於或高於當前收盤價,則將其設置為1。現在讓我們定義一個函數,該函數使我們能夠創建需要饋入神經網路的移動時間窗口:
def sequelize(x):
data = x.copy()
buys = []
sells = []
holds = []
data_length = len(data)
for index, row in data.iterrows():
if index <= data_length - WINDOW:
last_index = index + WINDOW -1
rowset = data[index : index + WINDOW]
row_stats = rowset.describe().transpose()
last_close = rowset['c'][last_index]
future_close = rowset['future_value'][last_index]
rowset = 2 * (rowset - row_stats['min']) / (row_stats['max'] - row_stats['min']) - 1
rowset.drop(['future_value'], axis=1, inplace=True)
rowset.fillna(0, inplace=True)
category = define_output(last_close, future_close)
if category == 1:
buys.append([rowset, category])
elif category == 0:
sells.append([rowset, category])
min_len = min(len(sells), len(buys))
results = sells[:min_len] + buys[:min_len]
return results
sequences = sequelize(data)
哦,好,那邊有很多東西。讓我們一點一點地看一下:
data = x.copy() # let's copy the dataframe, just in case
buys = []
sells = []
holds = []
data_length = len(data)
在這裡,我們正在做一些初步的工作,複製數據框以確保我們不覆蓋它(例如,如果您使用Jupyter Notebook可能會很煩人),並設置用於買賣的數組,我們將使用它們來平衡數據。
for index, row in data.iterrows():
if index <= data_length - WINDOW:
last_index = index + WINDOW -1
rowset = data[index : index + WINDOW]
如果索引大於我們定義的窗口大小,則在迭代數據中心化的每一行時,我們可以創建數據集的新切片,即窗口大小的大小。在將數據存儲到另一個數組中之前,我們需要使用以下代碼對其進行規範化:
row_stats = rowset.describe().transpose()
last_close = rowset['c'][last_index]
future_close = rowset['future_value'][last_index] # we'll need to save this separately from the rest of the data
rowset = 2 * (rowset - row_stats['min']) / (row_stats['max'] - row_stats['min']) - 1
而且我們還想從數據中心化刪除future_value,並用0替換任何可能的NaN(對於我們的目的而言,理想情況還不夠好):
rowset.drop(['future_value'], axis=1, inplace=True)
rowset.fillna(0, inplace=True)
最後,我們要確保我們的買賣平衡,如果其中一種發生的頻率比另一種發生的頻率高,我們的網路將迅速偏向偏斜,並且無法為我們提供可靠的估計:
if category == 1:
buys.append([rowset, category])
elif category == 0:
sells.append([rowset, category])
# the following 2 lines will ensure that we have an equal amount of buys and sells
min_len = min(len(sells), len(buys))
results = sells[:min_len] + buys[:min_len]
return results
最後,我們對數據運行此功能 sequences = sequelize(data)
隨機化我們的數據也是一個好主意,這樣我們的模型就不會受到數據集排序的精確順序的影響,以下代碼將對數據集進行隨機化,將訓練數據集與測試數據集進行拆分,並同時顯示這兩種數據中的買入與賣出分布數據集。隨時重新運行此代碼段,以確保更均衡地分配購買和出售:
random.shuffle(sequences)
def split_label_and_data(x):
length = len(x)
data_shape = x[0][0].shape
data = np.zeros(shape=(len(x),data_shape[0],data_shape[1]))
labels = np.zeros(shape=(length,))
for index in range(len(x)):
labels[index] = x[index][1]
data[index] = x[index][0]
return data, labels
x_train, y_train = split_label_and_data(sequences[: -VALIDATION_SAMPLES])
x_test, y_test = split_label_and_data(sequences[-VALIDATION_SAMPLES :])
sns.distplot(y_test)
sns.distplot(y_train)
len(y_train)
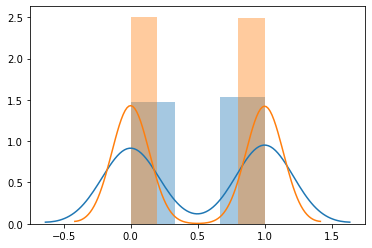 在運行了一段代碼後,您應該得到類似的東西,兩個數據集之間的買賣均分(左對右)。
在運行了一段代碼後,您應該得到類似的東西,兩個數據集之間的買賣均分(左對右)。
訓練模型
現在我們已經準備好訓練模型,但是由於我們尚未探索哪種超參數最適合我們的模型和數據,因此我們將嘗試一種稍微複雜的方法。首先讓我們定義四個超參數數組:
DROPOUTS = [
0.1,
0.2,
]
HIDDENS = [
32,
64,
128
]
OPTIMIZERS = [
'rmsprop',
'adam'
]
LOSSES = [
'mse',
'binary_crossentropy'
]
然後,我們將遍歷每個數組以訓練帶有超參數組合的模型,以便以後可以使用TensorBoard比較它們:
for DROPOUT in DROPOUTS:
for HIDDEN in HIDDENS:
for OPTIMIZER in OPTIMIZERS:
for LOSS in LOSSES:
train_model(DROPOUT, HIDDEN, OPTIMIZER, LOSS)
現在,我們需要定義train_model將實際創建和訓練模型的函數:
def train_model(DROPOUT, HIDDEN, OPTIMIZER, LOSS):
NAME = f"{HIDDEN} - Dropout {DROPOUT} - Optimizer {OPTIMIZER} - Loss {LOSS} - {int(time.time())}"
tensorboard = TensorBoard(log_dir=f"logs/{NAME}", histogram_freq=1)
model = Sequential([
LSTM(HIDDEN, activation='relu', input_shape=x_train[0].shape),
Dropout(DROPOUT),
Dense(HIDDEN, activation='relu'),
Dropout(DROPOUT),
Dense(1, activation='sigmoid')
])
model.compile(
optimizer=OPTIMIZER,
loss=LOSS,
metrics=['accuracy']
)
model.fit(
x_train,
y_train,
epochs=60,
batch_size=64,
verbose=1,
validation_data=(x_test, y_test),
callbacks=[
tensorboard
]
)
目前,這是一個非常簡單的模型,其中的LSTM層為第一層,一個Dense中間層,一個大小為1並sigmoid激活的Dense輸出層。該層將輸出概率(範圍從0到1),WINDOW在LOOKAHEAD間隔之後,特定大小的序列將跟隨較高的收盤價,其中0是較低的收盤價的高概率,而1是較高的收盤價的高概率。收盤價。
我們還添加了一個Tensorboard回調,這將使我們看到每種模型在每個訓練周期(EPOCH)的表現
隨意在您的終端中運行此代碼,然後運行Tensorboard tensorboard --logdir=logs
特徵工程
最好的模型在驗證數據上的準確性應該高於60%,這已經相當不錯了。但是,我們可以通過從現有數據中心化提取更多數據來快速改進模型。從現有特徵中提取新特徵的過程稱為Feature Engineering。特徵工程的示例是從數據中提取周末布爾值列,或從坐標對中提取國家/地區。在我們的案例中,我們將技術分析數據添加到我們的OHLC數據中心化。
在筆記本或文件的頂部,添加ta軟體包:from ta import *。
從csv載入數據後,添加以下行,它將以新列的形式將TA數據追加到我們現有的數據中心化
data = pd.read_csv('./data.csv')
#add the following line
add_all_ta_features(data, "o", "h", "l", "c", "v", fillna=True)
data['future_value'] = data['c'].shift(-LOOKAHEAD)
就是這樣,在幾行中我們極大地豐富了我們的數據集。現在,我們可以運行模型生成器循環來弄清楚我們的模型如何使用新的數據集,這將花費更長的時間,但值得等待。
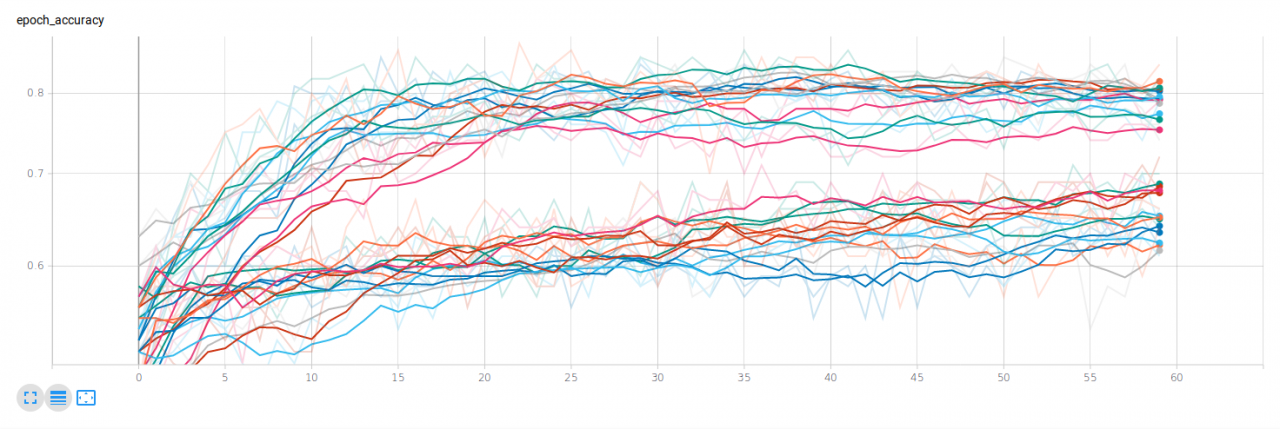
豐富,有意義的數據集應確保模型更準確,在上圖中,我們可以清楚地看到豐富數據集的性能比簡單數據集更好,驗證準確性徘徊在80%左右
評估性能最佳的模型。
現在我們有了一些看起來在紙面上表現不錯的模型,我們如何評估假設的交易系統中應該使用哪個模型?
這可能是相當主觀的,但是我認為一種好的方法是從已知的驗證標籤分別查看買入和賣出,並繪製相應預測的分布。希望,對於所有購買,我們的模型都可以預測購買,而不是很多出售,反之亦然。
讓我們定義一個顯示每個模型的K線走勢圖的函數:
def display_results(NAME, y_test, predictions):
plt.figure()
buys = []
sells = []
for index in range(len(y_test)):
if y_test[index] == 0:
sells.append(predictions[index])
elif y_test[index] == 1:
buys.append(predictions[index])
sns.distplot(buys, bins=10, color='green').set_title(NAME)
sns.distplot(sells, bins=10, color='red')
plt.show()
現在讓我們在每次完成模型訓練時都調用此函數:
model.fit(
x_train,
y_train,
epochs=60,
batch_size=64,
verbose=0,
validation_data=(x_test, y_test),
callbacks=[
tensorboard
]
)
# after the model.fit call, add the following 2 lines.
predictions = model.predict(x_test)
display_results(NAME, y_test, predictions)
隨著不同模型的訓練,我們現在應該看到與下圖類似的圖像,其中買入以綠色繪製(並且我們希望它們在右端,聚集在1值附近),賣出以紅色繪製(聚集在左側為0個值)。這些應有助於我們確定哪種模型可以提供更可靠的未來價格估算。
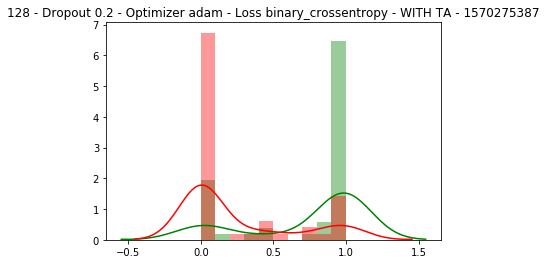
就是這樣,我們現在有一些原型可以使用,它們可以對未來的價格提供合理的估計。作為練習,請嘗試以下操作:
- 如果增加網路的隱藏層數會怎樣?
- 如果您的數據集不平衡會怎樣?
- 如果增加DROPOUT值會怎樣?
- 如果您在新數據上測試最佳模型會怎樣?(例如,通過從幣安獲取不同的時間戳?
如果您有任何問題或建議,請隨時在下面評測或建議對本文進行更新:)